YouTube will not let you play this video from this web site. Follow the link Watch this video on YouTube on the error page to see the video.
Recap on reinforcement learning
Case 1: a model for the environment is known.
Bellman equation can be used to calculate various quantities like the value function
v(s)=E[Rt∣St=s]+γs′∑Pss′v(s′)
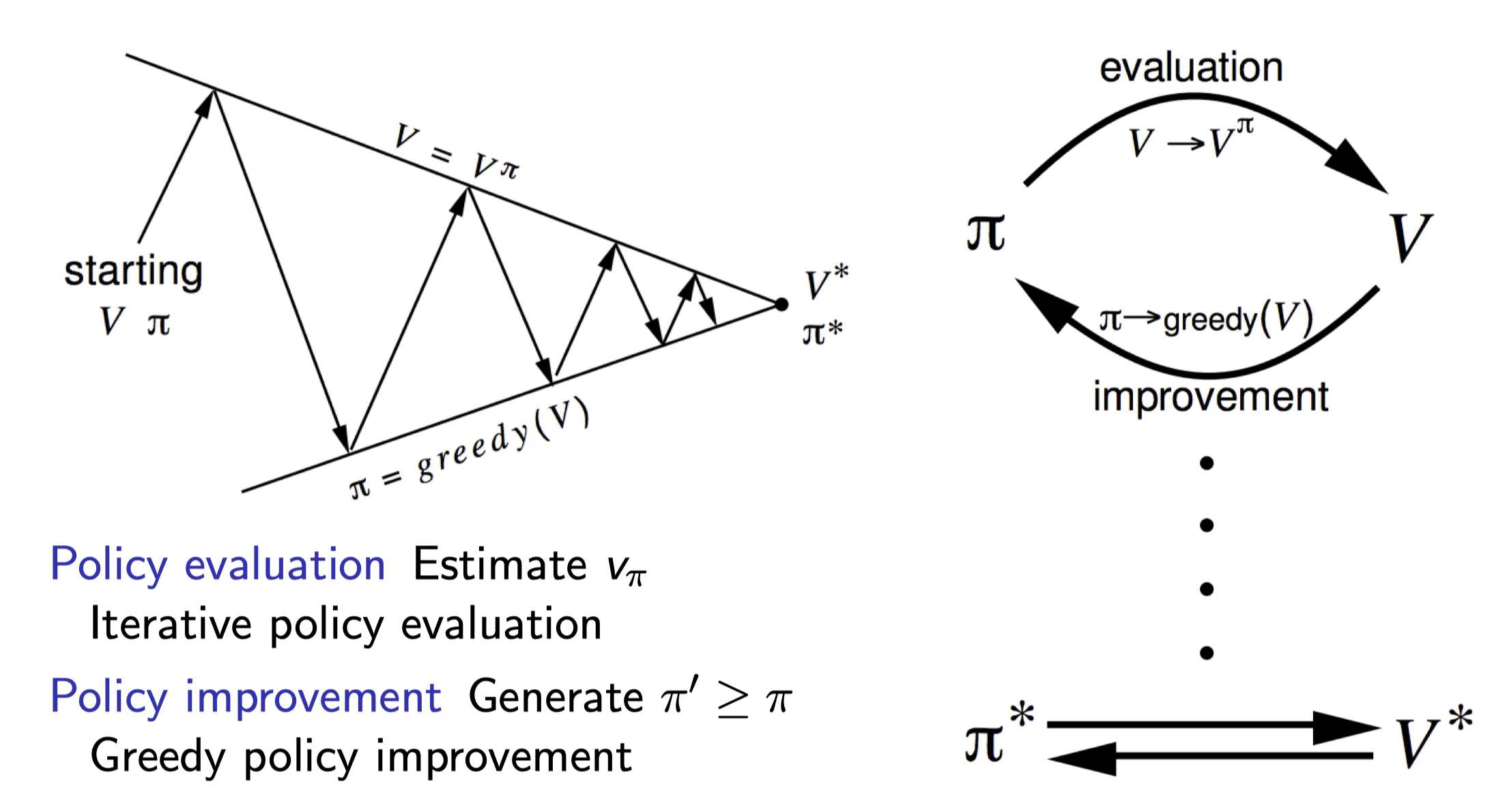
Control! Optimal value function
Iterate:
Policy evaluation: update value function based on policy vk+1(s)=a∑πk(a∣s)(Rsa+γs′∑Pss′avk(s′))
Policy improvement using greedy approach: argmaxa[Rsa+γs′∑Pss′avk+1(s′)]
Case 2: model-free learning
For cases where the environment is too large to be completely evaluated or simply unknown
Learn based on Monte-Carlo sampling
Full episodes
V(St)←V(St)+α(Gt−V(St))
Temporal-difference backup
V(St)←V(St)+α(Rt+1+γV(St+1)−V(St))
Policy gradient
Policy function may be approximated using a neural network
This allows using gradient methods to improve the policy
π(a∣s,θ)=P(At=a∣St=s,θt=θ)
θ: parameterization of π.
Example π(a∣s,θ)=∑aeϕ(s,a)⊤θeϕ(s,a)⊤θ
ϕ(s,a): vector of features; (ϕ1(s,a),…,ϕk(s,a)).
Policy gradient theorem (see notes)
Gradient used to update weights θ: ∇θJ(θ)∝Eπ[Gt∇θlnπ(At∣St,θ)]
Gt: discounted reward (MC sampling)
π(At∣St,θ): parameterized policy
There is a coefficient of proportionality but this is not important for gradient algorithms
REINFORCE algorithm
Algorithm:
Repeat until convergence:
Generate an episode S0, A0, R1,...,RT
using policy pi(theta)
For each step t of this episode:
G <- return at step t
Update theta using the eq. REINFORCE
θ←θ+αγtGt∇θlnπ(At∣St,θ)(REINFORCE)
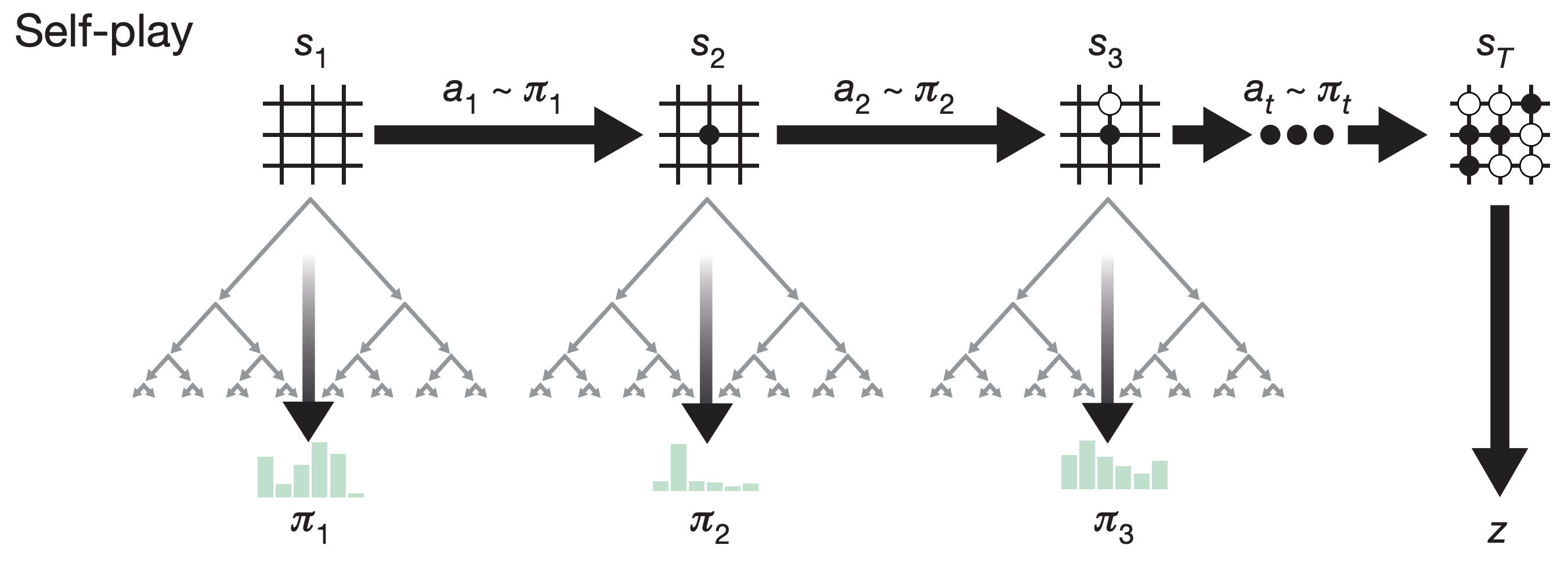
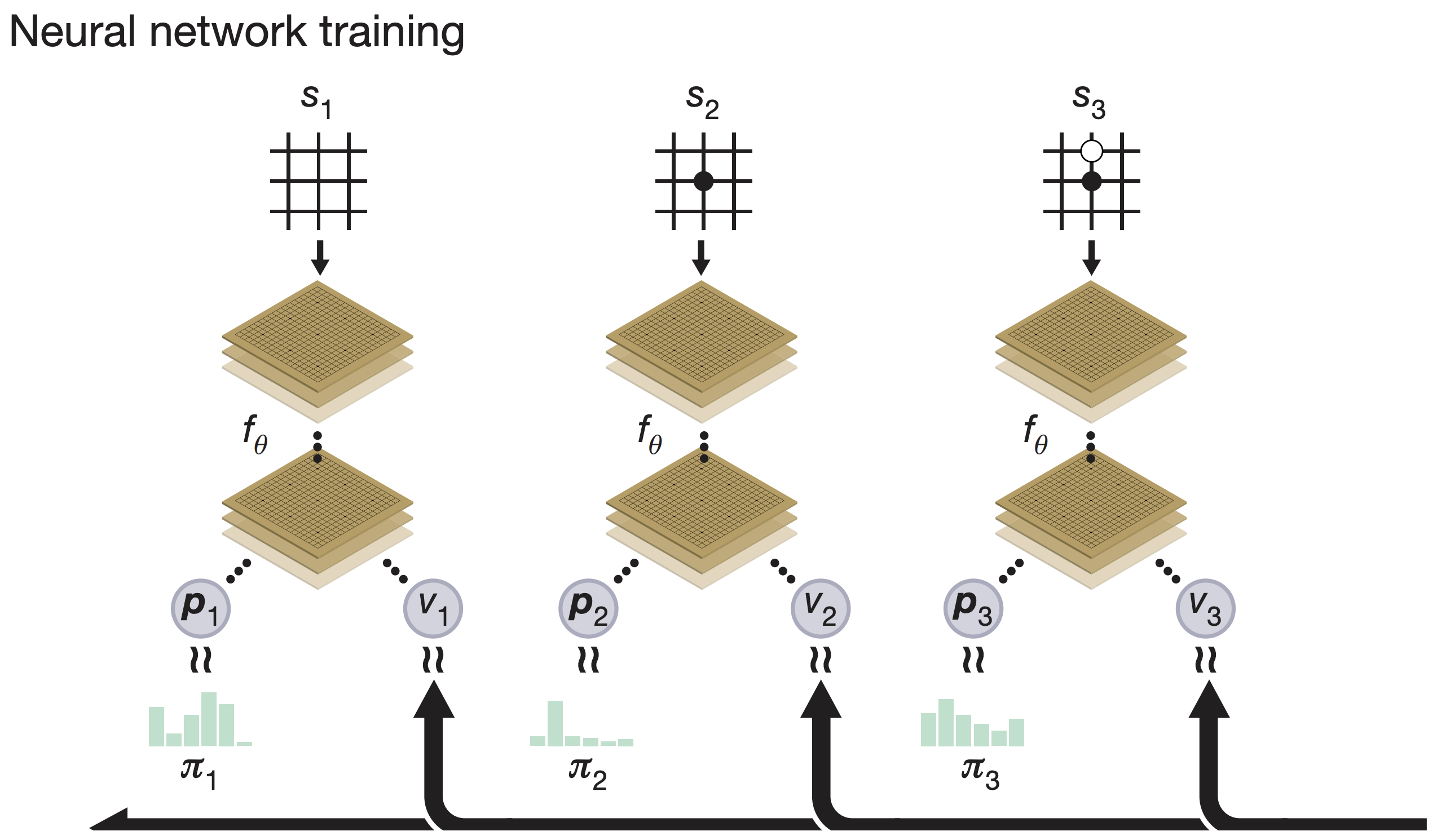
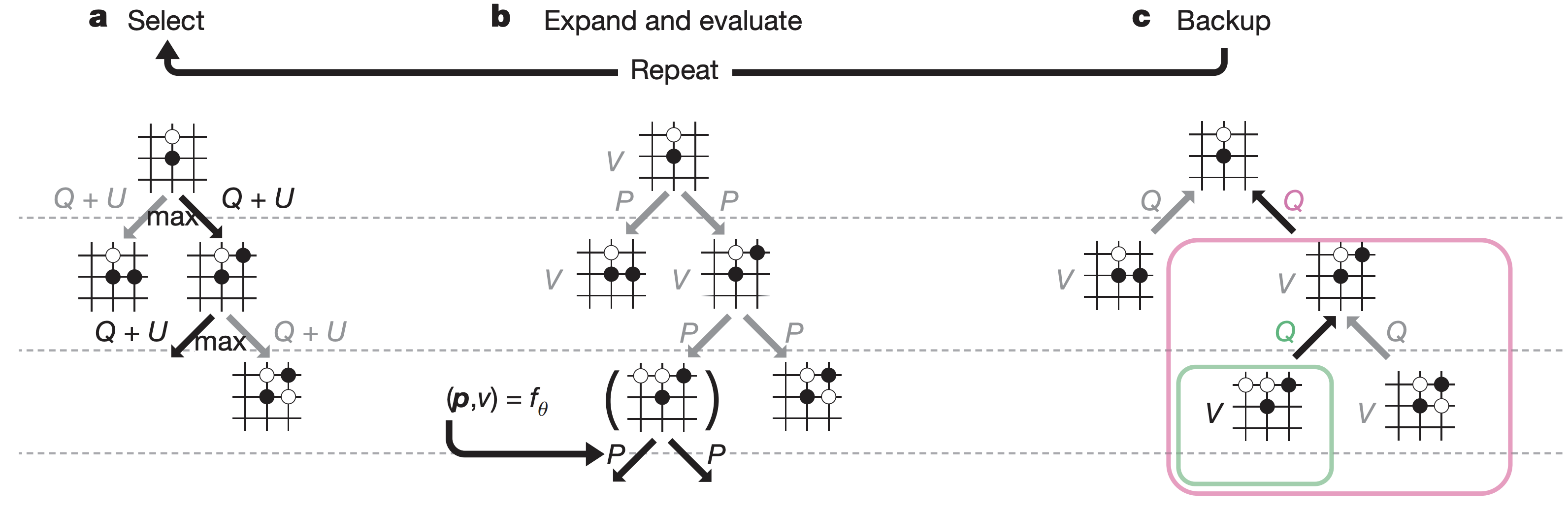
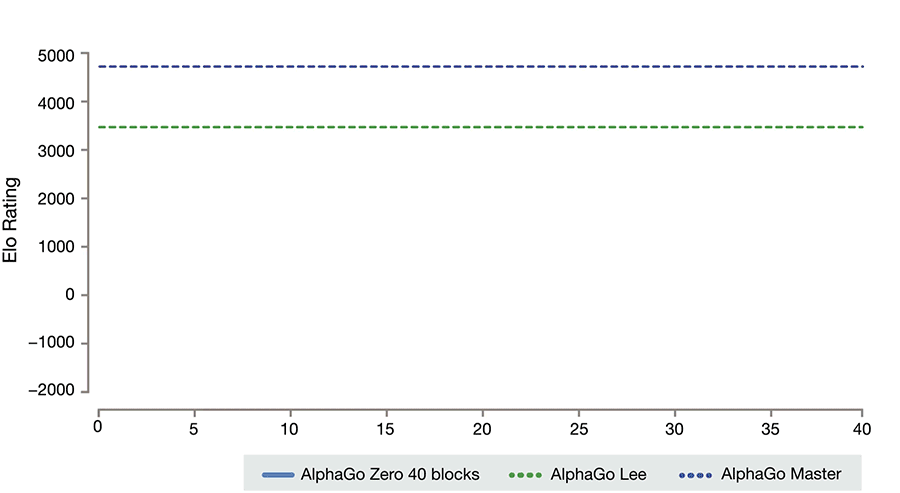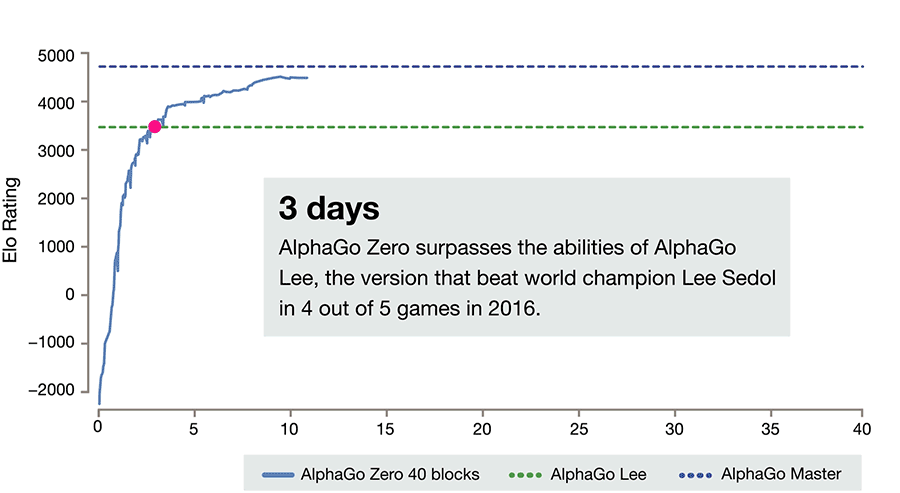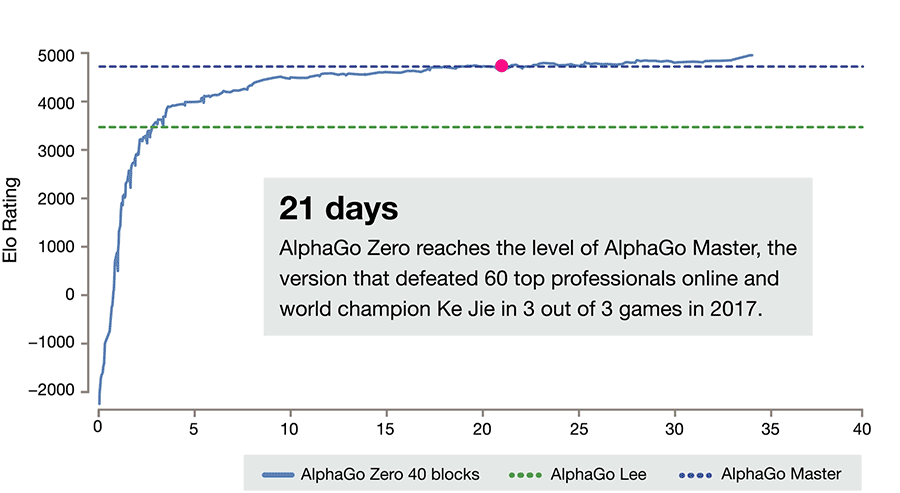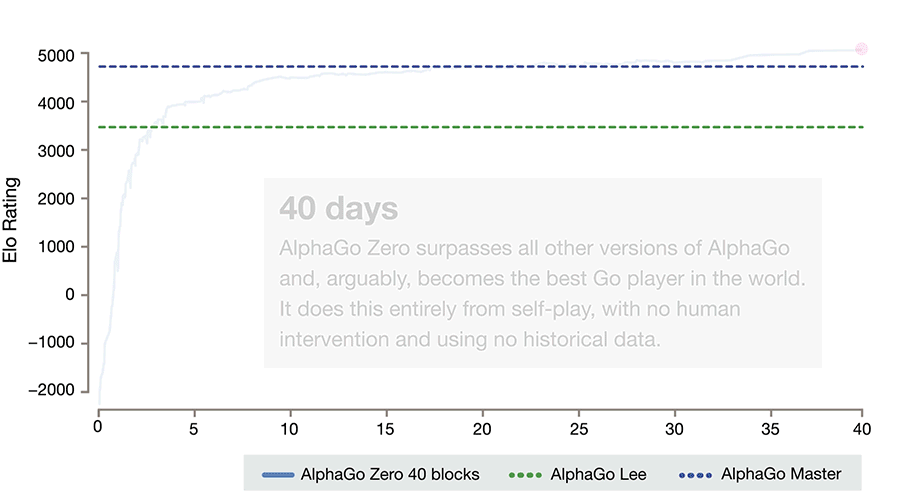
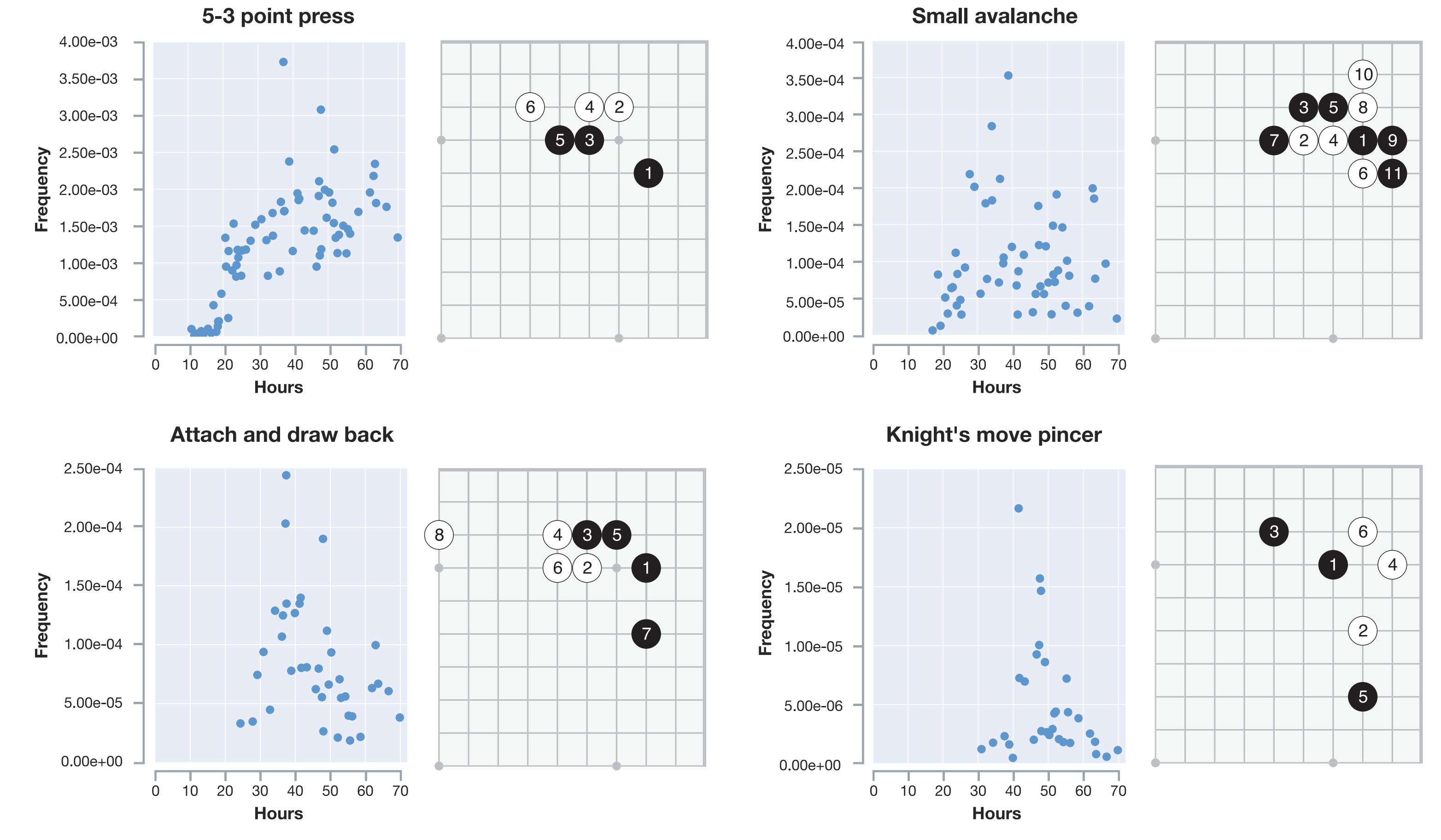
AlphaGo!
AlphaGo: computer program that defeated a Go world champion. Arguably the strongest Go player in history.